今天研究了怎么对图像分割出来的结果进行评估。这里先介绍dice方法,附加代码。简单明了,与网上抄来抄去的不一样。这里介绍的是npy形式,如果是Tensor需要将其转化成numpy。图片的mask掩码进行评估。
公式
公式网上有很多介绍,都是一样的,可以写成下面的形式:
$pred$指预测的结果,即预测出来的掩码 mask 的Tensor。
$true$指原来的真实的结果,也是掩码mask的Tensor形式。
$\cup$ 是并集。
$\cap$是交集。
$(pred\cap true)$代表的是预测结果与实际结果的相似的部分。
$(pred\cup true)$代表的是预测结果与实际结果合并起来的部分。
还是直接上例子,可以看的更清楚一点。
例子
预测的mask的图片是这样子的。
在mask里,黑色的是 False, 白色的是 True,则能得到下面这样的npy.1
2
3true_mask = np.array([[0,1,0],
[1,0,1],
[0,1,0]]).astype("bool")
输出为1
2
3
4# print(true_mask)
array([[False, True, False],
[ True, False, True],
[False, True, False]])
如果预测到的同样为
则其npy是这样的
1 | pred_mask = np.array([[0,1,0], |
输出为1
2
3
4# print(pred_mask)
array([[False, True, False],
[ True, False, True],
[False, True, False]])
我们可以看到,这个和真实的mask是一样的。
那他们的交集可以通过下面这个代码实现1
intersection = (output * target).sum()# 这里的output就是pred,target 是真实的标签
(output * target)的结果是:1
2
3array([[False, True, False],
[ True, False, True],
[False, True, False]])
这里不理解*乘法意义的同学,参考
https://blog.csdn.net/like4501/article/details/79753346
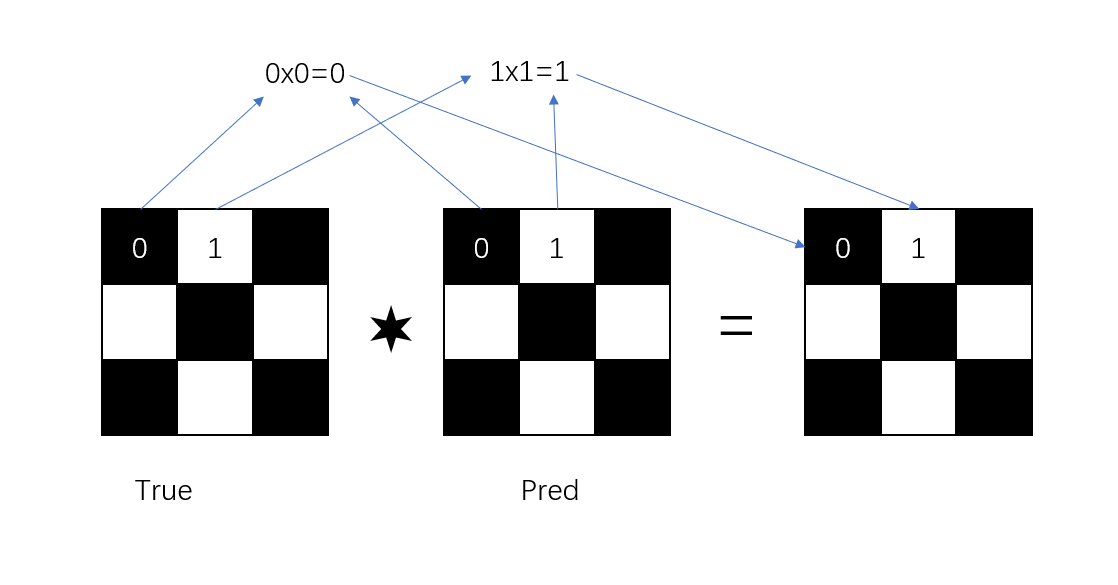
同时这里也给出图片解释:
这样就可以得到交集的部分,原理是,两个地方都有的部分,即为1的部分,相乘之后还是1,两个地方都没有的部分,相乘之后还是没有,两个地方,你为1,我为0的部分,相乘之后还是0。这里需要注意下的就是,取交集,取得是为1的交集。
之后对齐进行求和,得到的是4,代表有4个True,说明在预测过程中,有4个1相同。intersection的值,输出为4。
所以这里分子就是
这里分子上乘以了一个2,因为这里算出来的是重合的像素点(方块为1)的个数,分母是两个方块的面积相加,存在重复计算pred和true之间的共同元素的原因。
之后看分母,坟墓为两个sum再相加
得到的答案是8
之后分子分母相除,得到答案是1.0
接下来是全部代码
代码
1 | import torch |
这里可以更改一下预测,重新看一下结果。1
2
3pred_mask = np.array([[1,1,1],
[1,0,1],
[0,1,0]]).astype("bool")
可以获得其相似性是0.8000
npy文件的读入
这里增加一个npy文件的读取因为在获取图片掩码的时候,会将其存储在npy文件里,所以这里可以这样读取。1
2import numpy as np
test = np.load('/home/hjy/cmz/test_001/Test_001.npy')
输出来看一下1
2
3
4
5
6
7
8
9
10
11# print(test.shape)
(12224, 27648)
# print(test)
[[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]
...
[False False False ... False False False]
[False False False ... False False False]
[False False False ... False False False]]
这里没有看到 True 因为这个npy太大了,所以可以进行这样的操作,来找到哪里是True.1
print(np.where(test == True))
得到的结果是1
(array([ 39, 40, 40, ..., 12081, 12081, 12081]), array([ 263, 263, 264, ..., 16698, 16699, 16700]))
print(test[39][263])可以发现真的是True.
原创不容易啊
